自然言語処理ってそもそも何?実務への活用事例4選|東京のWEB制作会社・ホームページ制作会社|株式会社GIG
BLOG
ブログ
自然言語処理ってそもそも何?実務への活用事例4選
2019-03-09 ウェビナー・勉強会

こんにちは。GIG社員の松竹です。
今回は社外勉強会「Tech Trend Talk Vol.11 機械学習の応用と自然言語処理の活用」のレポートをお送りいたします。
今回の講師は、GIGの技術顧問兼外部取締役の中島さん。自然言語処理の活用法を紹介してくれました。
中島 正成(なかじま まさのり):株式会社メタップスの取締役CTOとして立ち上げに参画。機械学習とデータサイエンスのプロダクトインプリメントに取り組む。その後、エン・ジャパン株式会社経営戦略室経てIGS株式会社に執行役員CTOとしてジョイン。教育領域へのA.I活用プロダクト開発に取り組む。
過去のTech Trend Talk「機械学習回」はこちら▼
- 中学生レベルの数学で学ぶ機械学習モデルとPythonライブラリの話
- 機械学習の教師なし学習をやってみる
- 機械学習の教師あり学習をやってみる
- ランダムフォレストを用いたスコア予測の実践
- データ処理と機械学習アルゴリズム
当日のスライドはこちら▼
そもそも自然言語とは

中島さん:「ここでは技術的に高度な話はせず、自然言語処理をサービスに応用するイメージが掴めるように説明していきます」
中島さん:「そもそも、「自然言語」とは何でしょうか。自然言語とは、意思疎通のために普段から人が話したり書いたりしていることばです。自然言語は新しい単語や若者ことばが生まれたり、文法が変化したり、逆に使われなくなったことばが出てきたりと流動的です。機械言語や人工言語のように、定義されたことばとは異なります」
中島さん:「この自然言語をコンピュータで処理する技術が自然言語処理です。」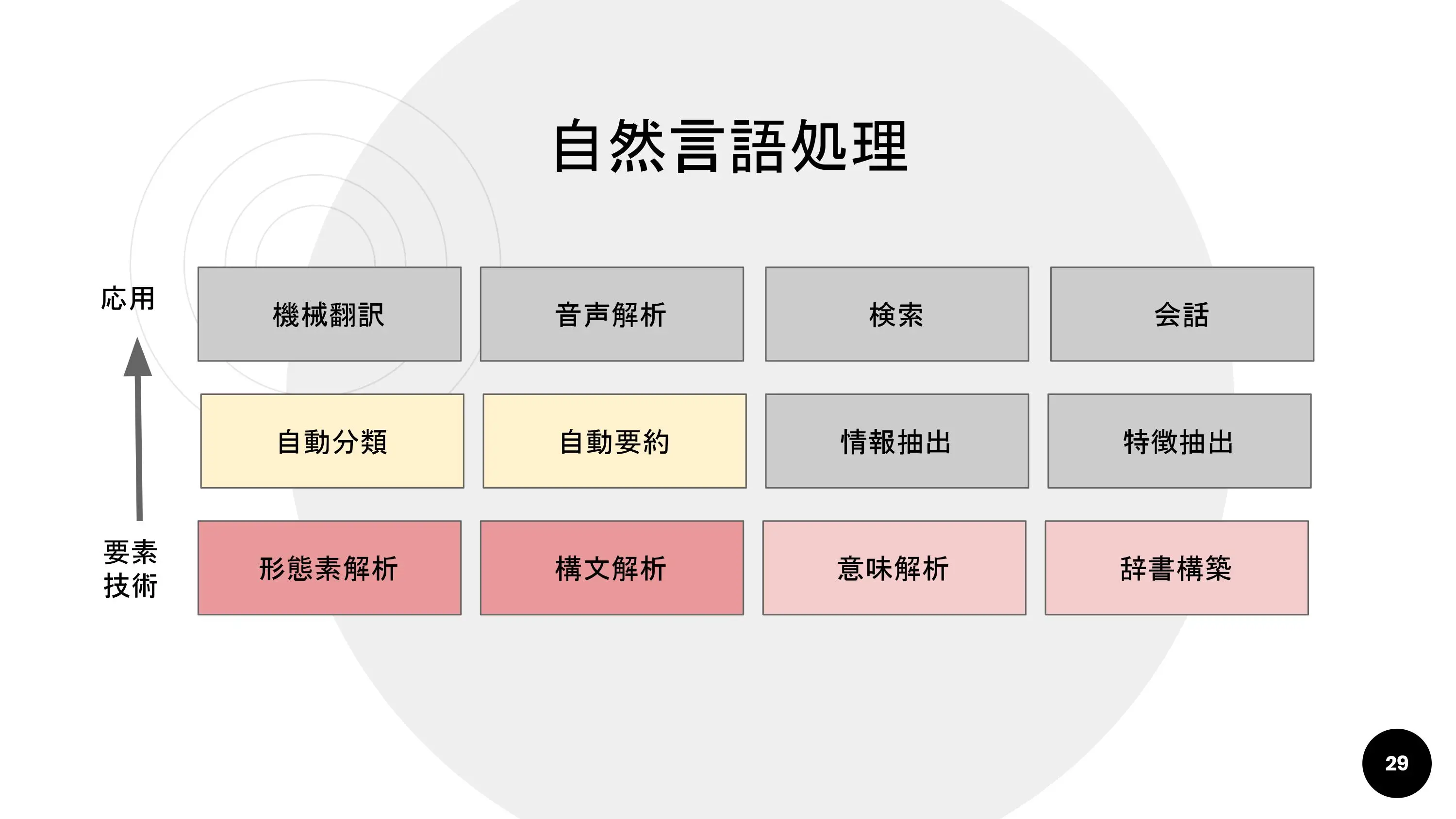
中島さん:「ひとくちに「自然言語処理」といっても、これを構成する要素技術はさまざま。応用されるサービスも幅広く派生します。」
中島さん:「今日は、もっとも基礎的な要素技術である形態素解析と構文解析・意味解析を簡単に紹介します」
形態素解析とは
中島さん:「「形態素」とは、単語よりももっと細かい、意味の通じる最小単位。この形態素を自動で判断して適切に仕分けるのが「形態素解析」で、あらゆる自然言語処理の基礎になる重要なテーマです。」
中島さん:「オープンソースの形態素解析エンジンもあります。日本語だとMeCab・Juman・Chasen、英語だとStanford NLP・PolyGrotが有名です。」
中島さん:「個人的にはJumanの精度が一番高い印象がありますが、いまもっとも一般的に使われているのはMeCabですね」 形態素解析の中身の技術にもさまざまなアプローチがありますが、基本的には辞書ベースの機械学習です。
形態素解析の課題は、「固有名詞の判断が難しい」という点です。例えば、私たちは当然のように『東京スカイツリー』を1単語と認識できますが、形態素解析エンジンは『東京/スカイ/ツリー』と分けてしまいがちです。
近年では、この問題を解決するための「キーワード抽出技術」の研究もされています。これは、文章を学習して「単語の組み合わせが頻繁に登場する場合、その組み合わせは固有名詞の可能性が高い」ということを機械学習で判断する技術です。
構文解析・意味解析
形態素から進んで、文節を判断してどのような係り受けの関係になっているかを判断するのが構文解析です。さらに進んで、単語や文章の意味を理解し、抽出する技術も研究されています。それが意味解析です。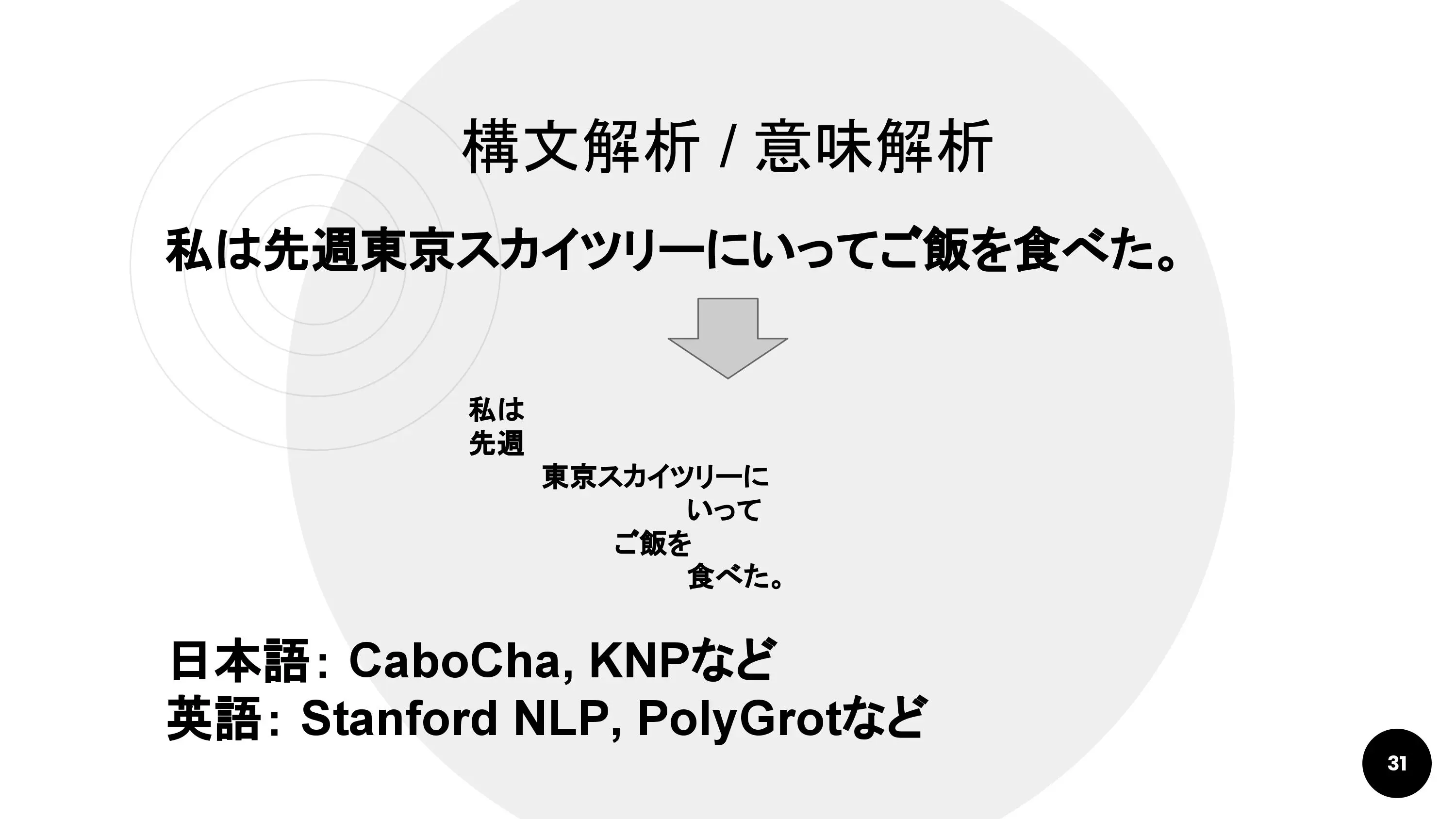
日本語の構文解析エンジンとしてはCaboCha、KNPが有名です。英語については、形態素解析の項で紹介したStanford NLP、PolyGrotが構文解析や意味解析にも対応しています。
どうやって自然言語処理を実務に活用していく?
では、どうやって自然言語処理を実務に活用すればいいのでしょうか。
中島さん:「基本的にはどんなサービスも、これまでに紹介した要素技術を組み合わせた上に成り立っています」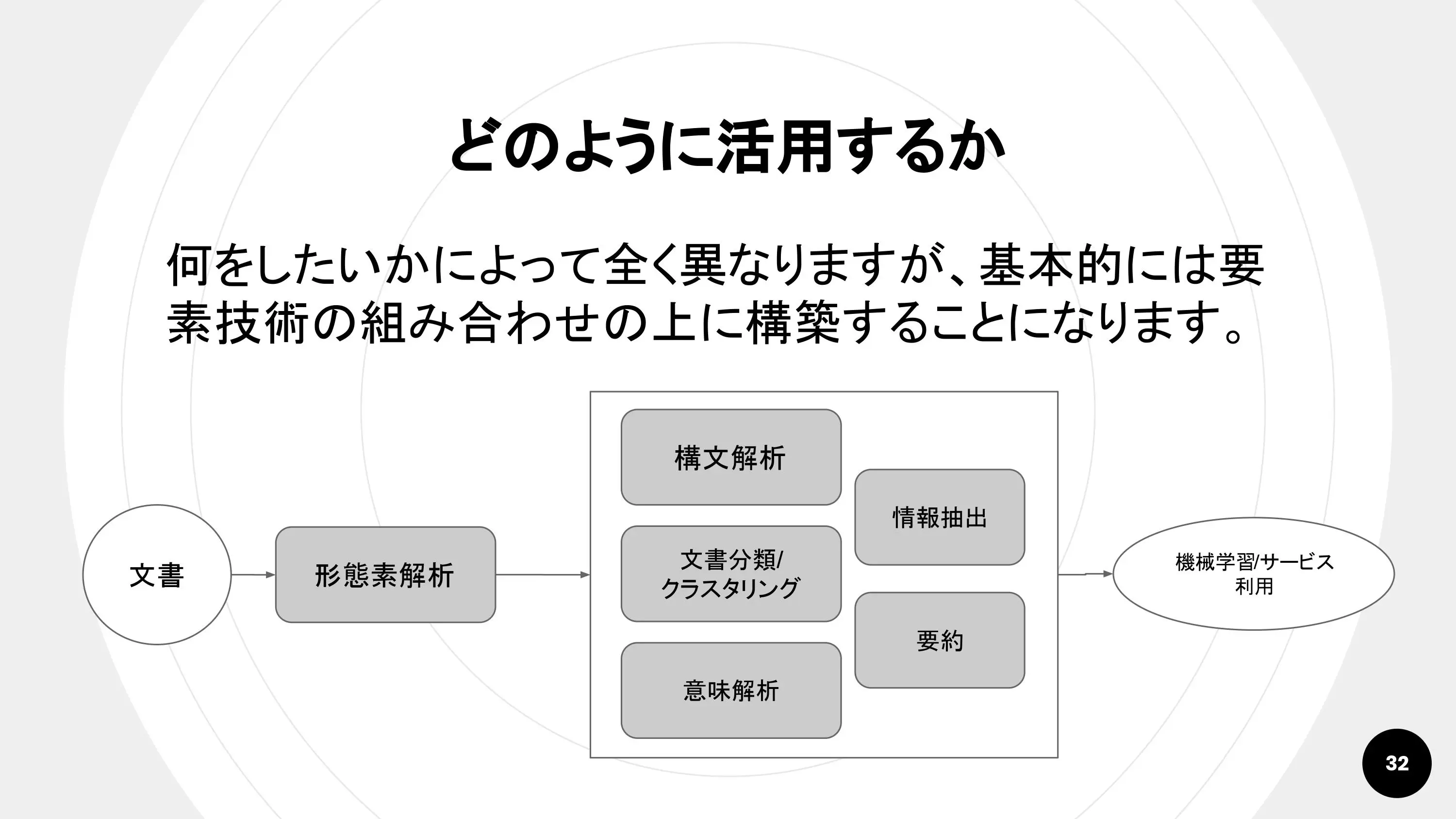
中島さんの紹介する「鉄板の流れ」は以下の通り。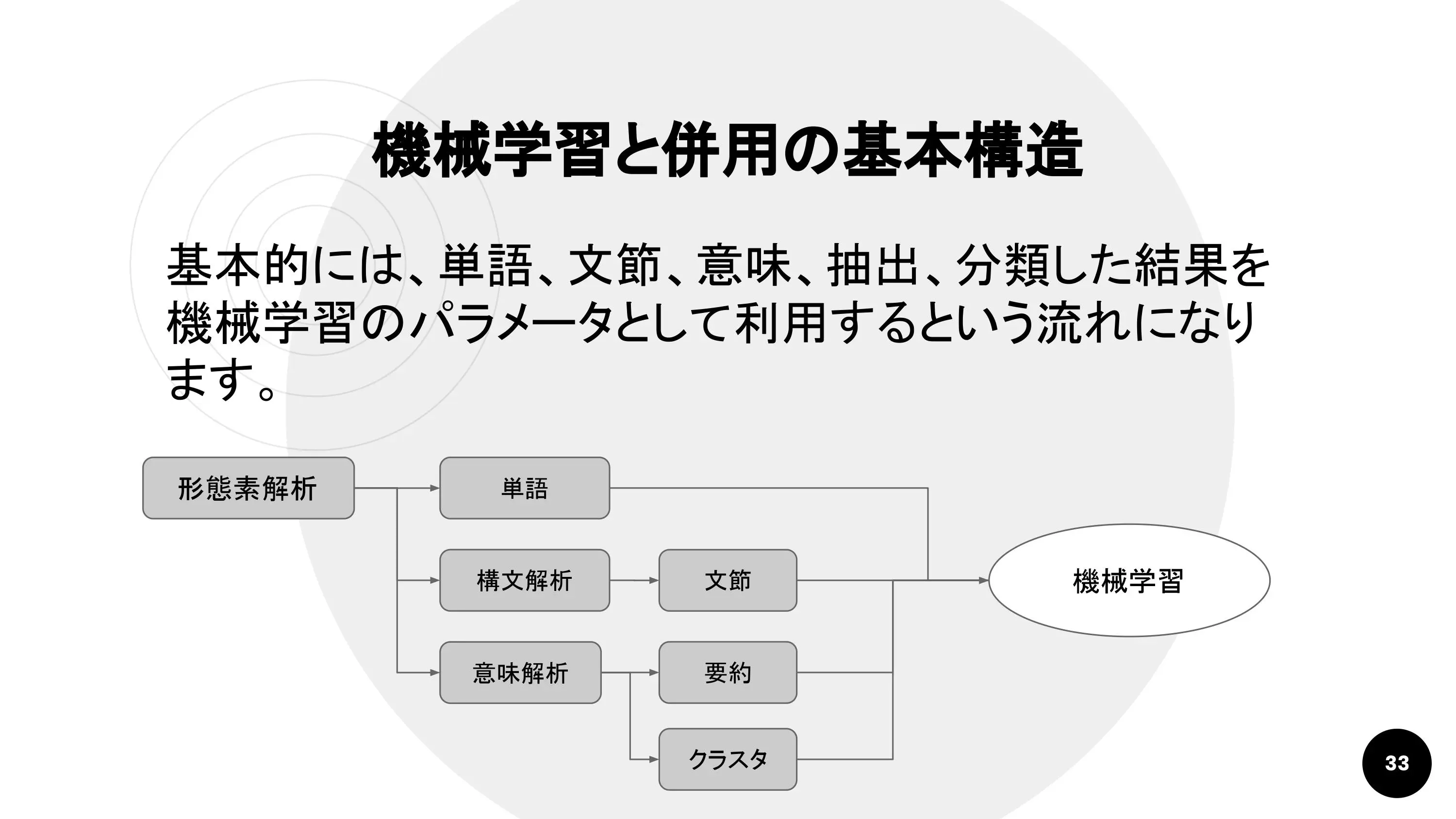
形態素解析を行い、単語を判別。さらに構文解析を通して文節を読み取り、それらをパラメータとして機械学習します。応用的ですが、自動要約した内容や、クラスタリングした結果も利用できます。
中島さん:「現場のエンジニアが陥りがちなのが、単語だけでとりあえず機械学習をしようとすると、新語や特徴的な語句への対応に開発・運用コストがかかります」
例えば、『課題解決力』をそのまま形態素解析すると『課題/解決/力』と分けられてしまいます。こういった語句をいちいち辞書登録するのは非常に大きな手間です。
ここで構文解析を用いれば、『課題解決力は』という文節で判断できます。その上で助詞『は』を取り除けば、『課題解決力』という単語を絞り込めます。
このように、文節や要約文をパラメータに用いることで、より精度の高い学習を簡単できることがあります。
中島さん:「それでは、自然言語処理をサービスに応用する方法を実例で紹介していきます」
例1. チャットボット
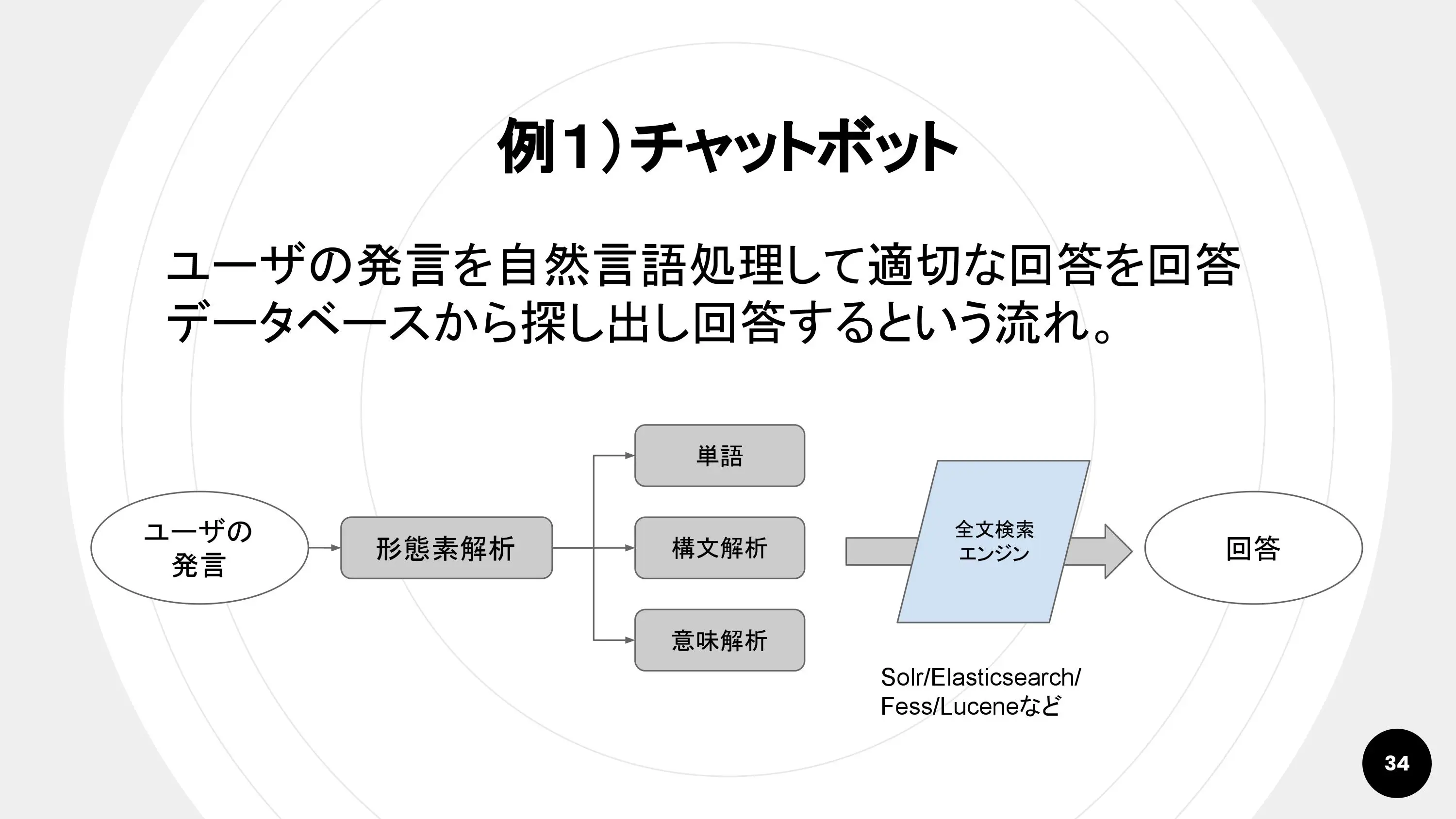
基本的なチャットボットの中身はこのようになっています。
回答文まで自動で生成するのは、ほかの非常に高度な技術が必要です。そのため、多くのチャットボットは、重要なキーワードを抽出して全文検索エンジンに掛け、最適な回答パターンを返すようになっています。
キーワードを選定する「ことばの重要度」を評価する手法には、tf-idfがあります。
例2. 記事の自動分類
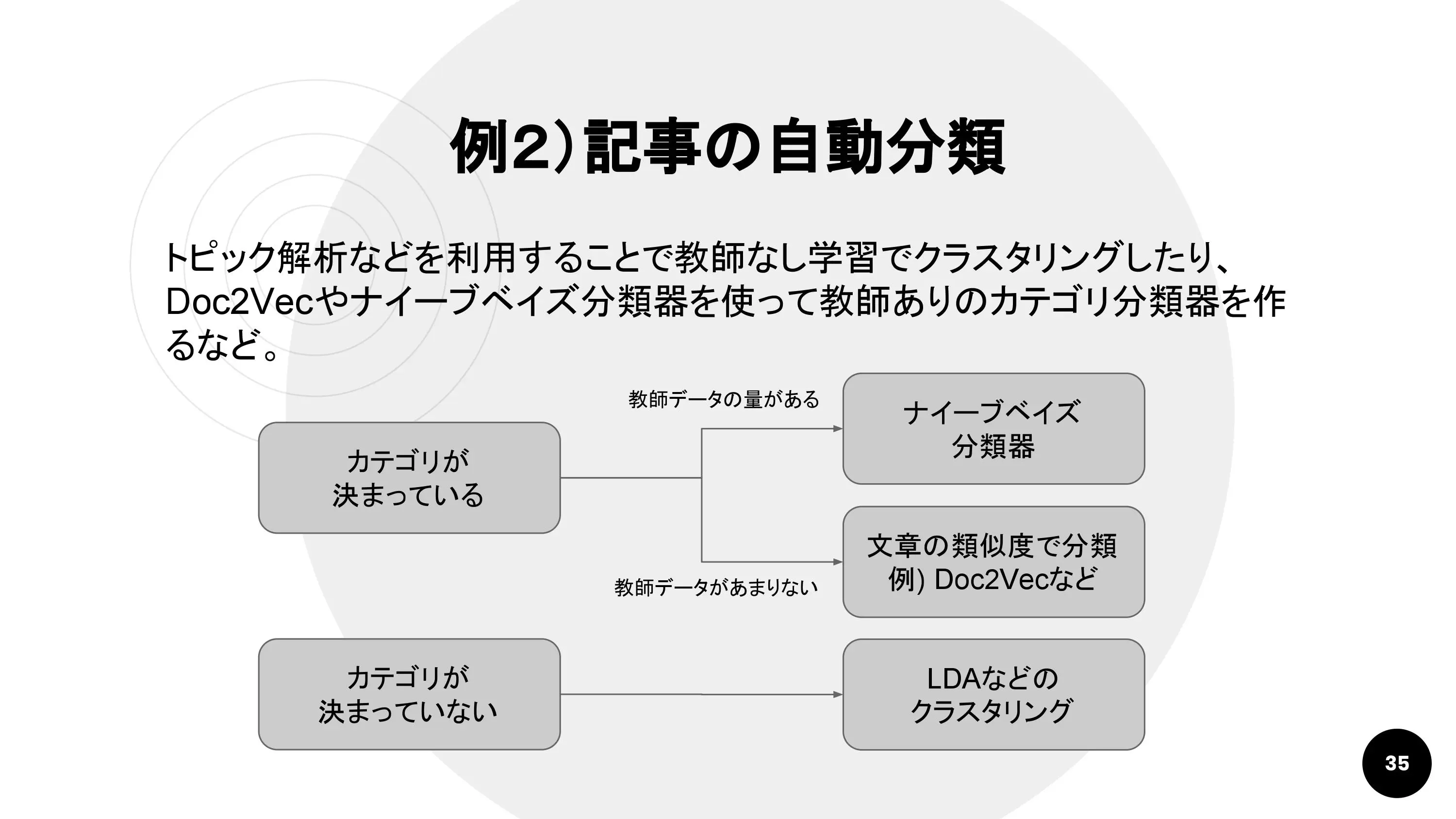
記事を自動的に分類する機能も自然言語処理を使えば導入できます。ユーザー投稿型サービスやキュレーションサービスだけでなく、ユーザーからの問い合わせを分類する機能や、プロフィールやユーザー行動を分析して記事をサジェストするタイプのマッチングシステムなどにも応用が効く技術です。
分類するカテゴリがあらかじめ決められ、教師データも十分ある場合におすすめなのが、ナイーブベイズ分類器という手法です。これはGoogleメールのスパム判定にも利用されています。
教師データが十分でなくても、似ている文章を探してカテゴリに当てはめていくやり方もあります。近年注目されているのはDoc2Vecという手法です。このほか、単語の出現回数で分類することもできます。この場合、単語だけでなく類語を参照したり、辞書的にカテゴライズされた単語データベース(日本語WordnetやWikidataなど)を参照したりすることで精度を高められます。
「カテゴリが決まってないが、とりあえず分けてみたい」というときには、トピック解析を行いましょう。代表的な手法はLDAです。
例3. ユーザ興味の要約
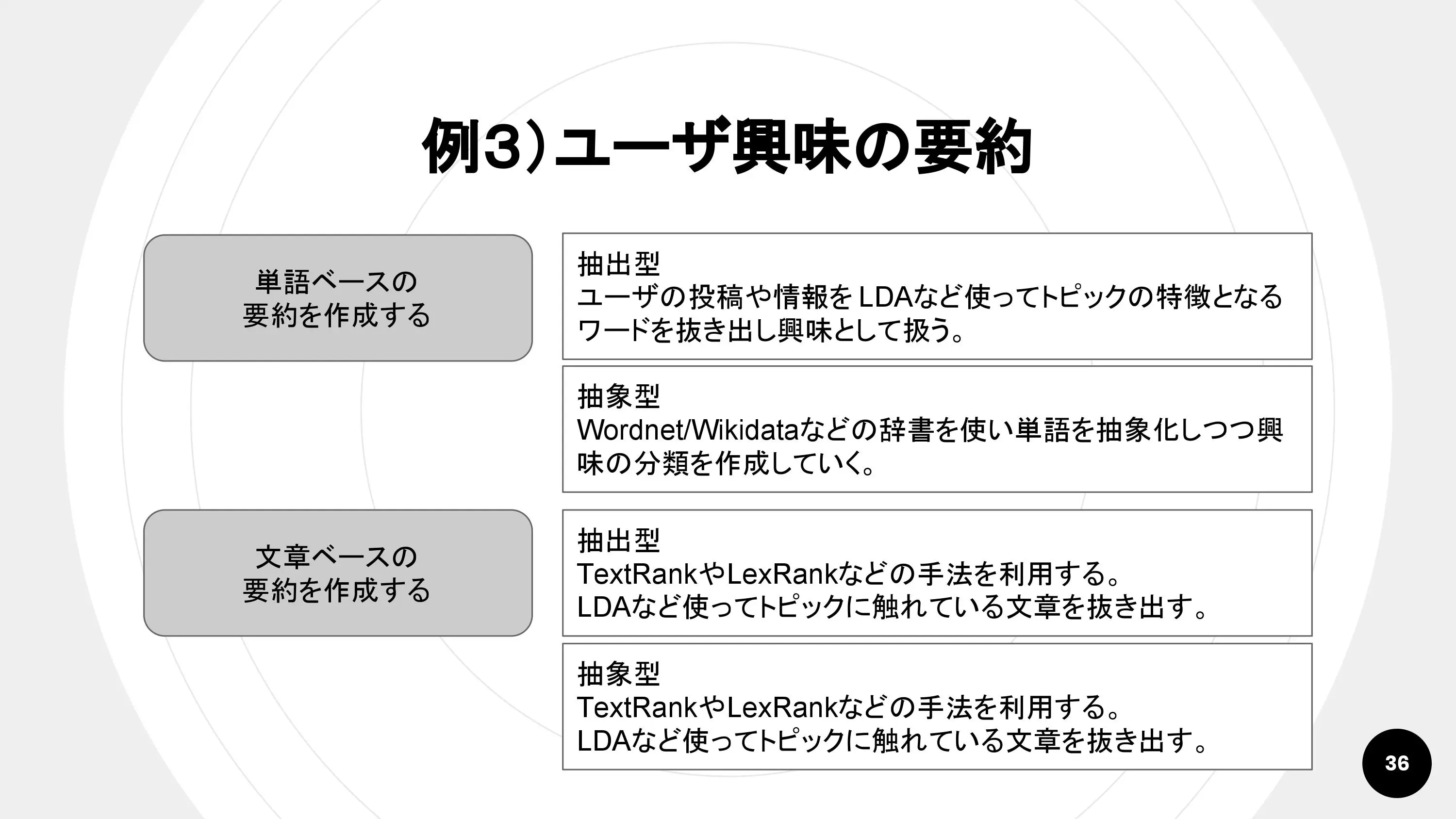
自動要約は、自己紹介文やブログ投稿からユーザープロフィールの要約を作るほか、Webサイトの要約文を自動生成したり、不正投稿を監視したりするのにも使える技術です。
要約パターンには、単語ベースでの要約と文章ベースでの要約の2種類があります。さらに、それぞれのパターンで抽出型(単語や文章をそのまま抜き出す)と抽象型(単語や文章をカテゴリに分類した上で抜き出す)の2種類に分けられます。
TextRankとLexRankは、記事のセンテンスどうしのつながりを読み取り、よりつながりが集中しているセンテンスを抽出するアルゴリズムです。
例4. 履歴書のスコアリング
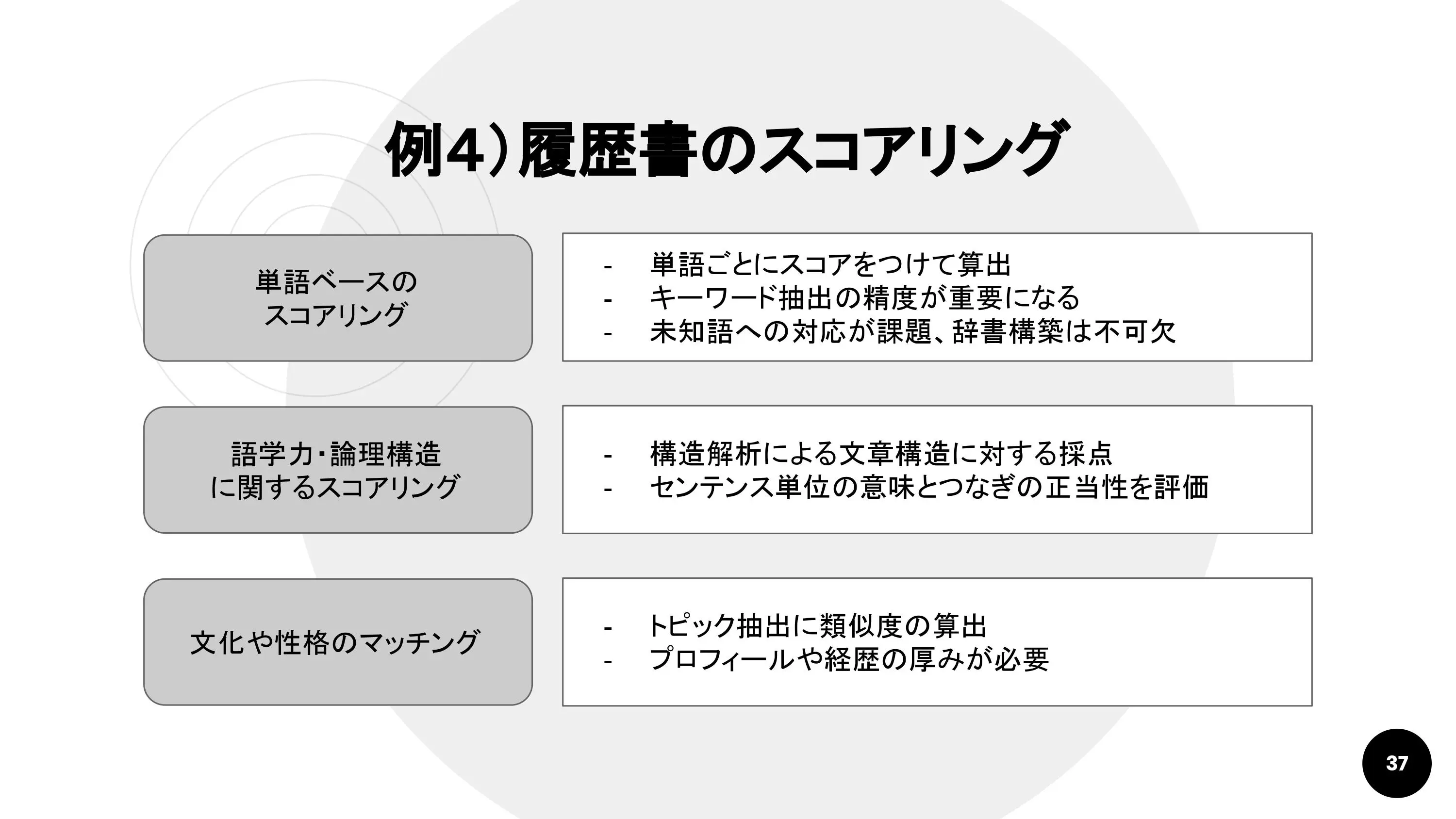
HRテック分野で注目を集めるのが履歴書(レジュメ)のスコアリング。有名なサービスにはTextioがあります。
Textioの優れている点は、採用候補者のレジュメから注目すべき点を単語レベルでハイライトしてくれる機能です。単語ごとにスコアを割り振って総合点を算出しています。
単語のスコアは、現在の社員のレジュメから割り出しているようです。ここでも、単語だけに注目すると新たな職能(例:データサイエンス)に対応できない可能性があるので、キーワード抽出技術が重要になります。
単語だけでなく、「論理構造が正しいか」「簡潔に書かれているか」といった要素をスコアリングするには、構造解析を使用します。
また、社内のスタッフのレジュメが集まっていれば、トピック抽出によって文化や性格のマッチングを探ることもできます。ただし、これには採用候補者のレジュメにも相応の厚みが必要です。
開発相談は株式会社GIGへ!

内容盛り沢山のトークを終え、中島さんもこの笑顔。集中してみんな勉強会に取り組んでいたため、お腹はペコペコ。用意したピザはあっという間になくなりました。
中島さんは、「機械学習さえすればすぐ何かしら効果があるのではない。あくまで、いままでのやり方を踏襲しながらその精度や効率を上げるために使う」ということを強調していました。ホットワードだからと飛びついても成果が得られるとは限りません。正しく扱ってはじめて武器になるのだと実感しました。
GIGでは機械学習、IoT、ブロックチェーンなどの最新トレンドに関する勉強会を今後も定期的に開催していきます。イベントの詳しい情報は、connpassのGIGページをチェックしてください!
WebやDXの課題、無料コンサル受付中!

GIG BLOG編集部
株式会社GIGのメンバーによって構成される編集部。GIG社員のインタビューや、GIGで行われたイベントのレポート、その他GIGにかかわるさまざまな情報をお届けします。
SHARE