SVM(サポートベクターマシン)を用いた「教師あり学習」をやってみる【機械学習スペシャリストが解説】|東京のWEB制作会社・ホームページ制作会社|株式会社GIG
BLOG
ブログ
SVM(サポートベクターマシン)を用いた「教師あり学習」をやってみる【機械学習スペシャリストが解説】
2018-08-18 ウェビナー・勉強会

こんにちは、株式会社GIGの岸です。毎日暑い日が続きますが、みなさんいかがお過ごしでしょうか。
さて、弊社GIGでは社外スピーカーをお招きした勉強会「Tech Trend Talk vol.5 機械学習の教師あり学習をやってみる」が開催されました。
機械学習の「教師あり学習」をやってみる
今回の講師は、GIGの技術顧問兼外部取締役の中島正成さん。「機械学習の教師あり学習」と題してSVM(サポートベクターマシン)を使った教師あり学習の実装方法を教えてくださいました。

中島 正成:株式会社メタップスの取締役CTOとして立ち上げに参画。機械学習とデータサイエンスのプロダクトインプリメントに取り組む。その後、エン・ジャパン株式会社経営戦略室経てIGS株式会社に執行役員CTOとしてジョイン。教育領域へのA.I活用プロダクト開発に取り組む。
当日使用したスライドは以下からご覧いただけます。
「教師あり学習」とは過去のデータをもとに未来を予測・分類する方法

「教師あり学習」とは、機械学習の手法の一つです。すでに答えのわかっている過去のデータから未来を予測・分類する方法を指します。
中島さん:
「教師あり学習をおこなう場合は、過去のデータから未来を予測・分類する方法なので正解データを用意する必要があります」
中島さん:
「今回はSVM(サポートベクターマシン)を用いた教師あり学習を実際にやってみます」
SVM(サポートベクターマシン)とは
SVM(サポートベクターマシン)は、教師あり学習を用いるパターン認識モデルの一つです。分類や回帰へ適用できます。
中島さん:
「SVM(サポートベクターマシン)は、分類モデルの中でも非常に汎用性が高く、よく使われるアルゴリズムです」
中島さん:
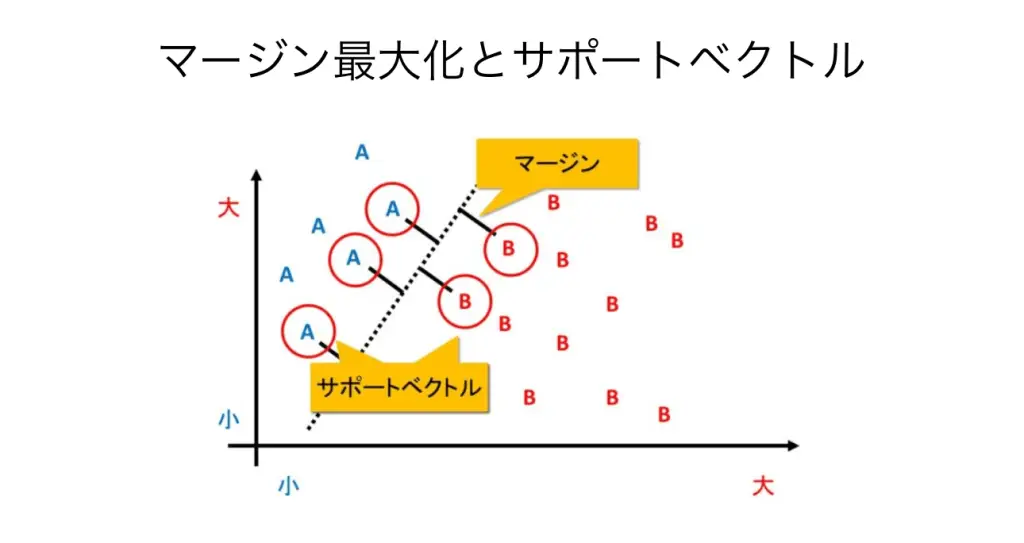
「SVMは、マージンを最大化しサポートベクトルを見つけ出すことで、たくさんあるデータを分類する方法です」
中島さん:
「SVMでは、ある2つの答えがあらかじめわかっているデータAとBを分けるときに、サポートベクトル全ての長さが均等になる線を探索する学習をします」
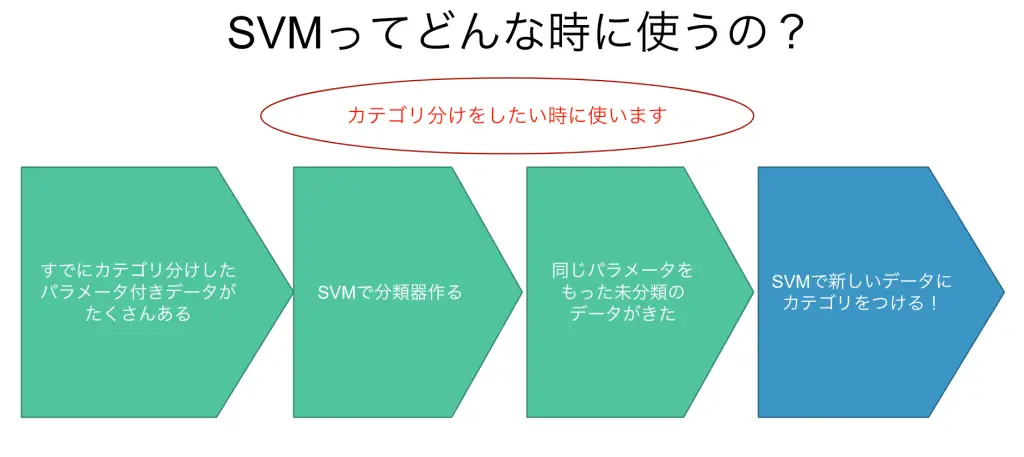
SVMは、パターン認識なので、自動的にデータを分類したいときに使うことができます。主な使用例は以下です。
- 投稿された記事を自動的に分類する
- 商品を自動的に分類する
- 人の情報から人自体を分類する
中島さん:
「リアルタイムに仕分けをしたいデータが蓄積される場合や、コミュニティサイト上で記事を投稿した際のタグ付けにも応用できます」
環境構築をしよう
実際にSMVを使った教師あり学習をする前に、環境を構築します。環境構築は以下の方法です。
- Pythonをインストールする
- jupyter-notebookで新規ファイルを作成&データを読み込んでみる
詳しい環境の構築方法は、前回の勉強会レポートを参照してください。
教師あり学習をやってみよう

今回の教師あり学習では、正解データとしてscikit-learnに付属しているIrisというデータセットを使います。Irisデータセットは“setosa”“versicolor”“virginica” という 3 種類の品種のアヤメのがく片 (Sepal)、花弁 (Petal) の幅および長さを計測したデータです。
1. 新しいnotebookを作る
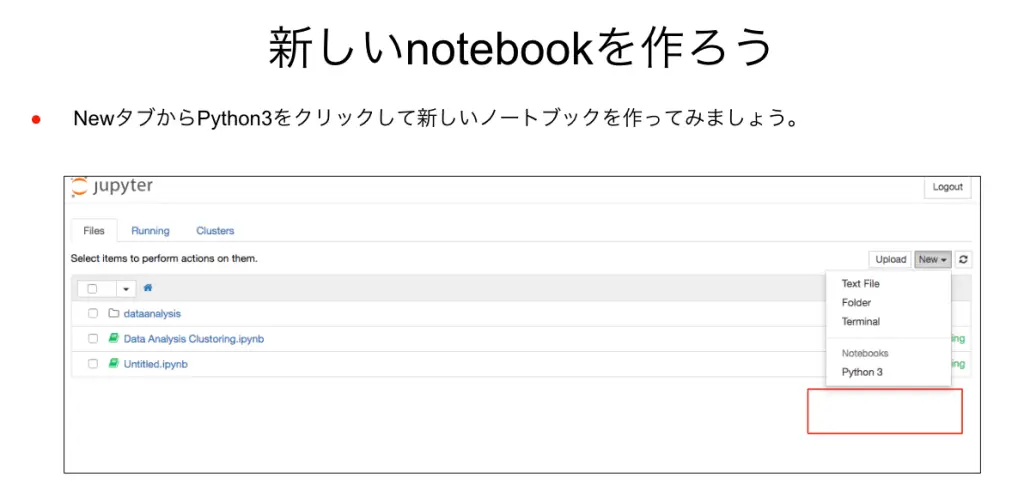
jupyter-notebookのNewタブから、Python3をクリックして新しいノートブックを作成します。
2. データを読み込む
notebookの作成ができたらデータの読み込みをおこないます。
中島さん:
「SVMを使うにあたってたくさんのライブラリをインポートしています」
中島さん:
「train_test_spilitライブラリは、正解データが用意できた場合に5〜7割程度を機械学習に使って残りのデータをテスト用のデータに自動的に分類してくれる便利なライブラリです」
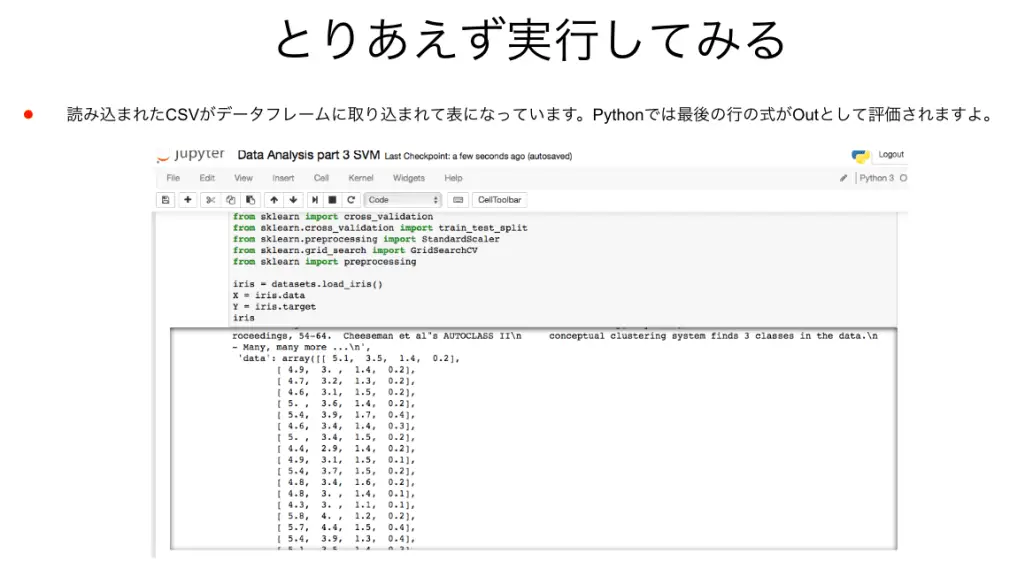
データ読み込みのコードを実行してみると、Irisデータセットのデータが読み込まれます。
3. データを学習用と検証用に分けて標準化する
先ほど読み込んだデータを学習用と検証用に分けます。学習用と検証用にデータを分けて学習することで、学習の精度を検証できます。
中島さん:
「この手法は、実際のプロダクトを作る際の学習でもよく用いられる手法です」
次に、学習用データを使ってトレーニングをします。
中島さん:
「scikit-learnでは、fit関数でデータを与えるとトレーニングが実行されます」
4. 実際に予測してみる

トレーニングが完了したあと、実際にデータを入力し予想をすることで、正解率を検証します。
中島さん:
「トレーニングデータをそのまま検証させても正解率は100%になりません。これはデータを分類する線引きの角度に誤差が生じるからです」
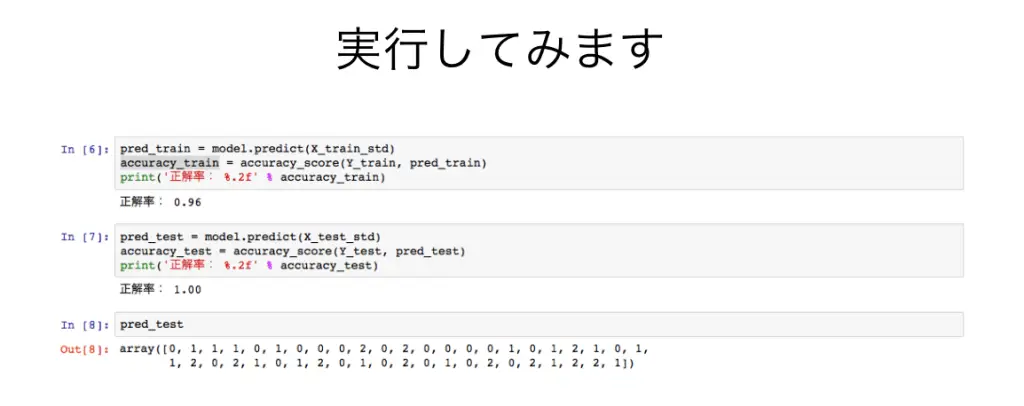
プログラムを実行してみると、正解率は上の画像のようになりました。検証用データの予測が100%の正解率です。
中島さん:
「Irisデータセットは予測のしやすいデータであることがわかります」
中島さん:
「実際のプロダクトでは、SVMで予測したデータは正解率が6割くらいでも優秀な結果といえます」
SVMに関するQ&A

Q1:
SVMを使って画像の分類をすることはできないのか?
A1:
SVMは分類問題に関しては汎用的に利用できます。
中島さん:
「たとえば、SVMを使った画像認識を応用することで、筆跡を鑑定できます」
Q2:
処理スピードはどの程度なのか?
A2:
SVMの一番の特徴はトレーニングや予想が早いところです。
中島さん:「SVMがよく使われる理由は、トレーニングや予想にコストがかからないからです」
まとめ

勉強会のあとは懇談会のお時間です! 参加者のみなさまは各々お酒やソフトドリンクを手に、乾杯しました!

お酒を片手に中島さんに質問をするなど、社内外関係なく交流できる場はとても貴重です。

GIGでは月1回のペースで社外向けの勉強会を開催しています。エンジニアに限らず、デザイナーやディレクターなども勉強会に参加しており、全社的なスキル向上の良い機会となりました。
中島さんの説明は、プログラミング初心者の僕にもわかりやすかったので、機械学習に対する興味が湧きました。
GIGでは機械学習、IoT、ブロックチェーンなどの最新トレンドに関する勉強会を今後も定期的に開催していきます。イベントの詳しい情報は、connpassのGIGページをチェックしてください!
WebやDXの課題、無料コンサル受付中!

GIG BLOG編集部
株式会社GIGのメンバーによって構成される編集部。GIG社員のインタビューや、GIGで行われたイベントのレポート、その他GIGにかかわるさまざまな情報をお届けします。
SHARE