K-means(K平均法)を使って「教師なし学習」をやってみる【機械学習スペシャリストが解説】|東京のWEB制作会社・ホームページ制作会社|株式会社GIG
BLOG
ブログ
K-means(K平均法)を使って「教師なし学習」をやってみる【機械学習スペシャリストが解説】
2018-06-14 ウェビナー・勉強会

こんにちは、株式会社GIG 編集者 兼 ライターのじきるうです!
GIGでは社外スピーカーをお招きした勉強会「Tech Trend Talk vol.3 機械学習の教師なし学習をやってみる」が開催されました。
機械学習の「教師なし学習」をやってみる
今回の講師は、GIGの技術顧問兼外部取締役の中島正成さん。「機械学習の教師なし学習」と題して、前回に続いて機械学習の教師なし学習を実装する方法を教えてくれました。

中島 正成:株式会社メタップスの取締役CTOとして立ち上げに参画。機械学習とデータサイエンスのプロダクトインプリメントに取り組む。その後、エン・ジャパン株式会社経営戦略室経てIGS株式会社に執行役員CTOとしてジョイン。教育領域へのAI活用プロダクト開発に取り組む。
当日使用したスライドは以下からご覧いただけます。
「教師なし学習」とは、乱雑なデータの共通項を分類しデータの精度を高める手法
「教師なし学習」とは、ざっくりとした情報を与えることで、乱雑なデータの共通項を分類しデータの精度を高める手法です。正解があらかじめ決まっていない場合に用いられ、通常はビックデータの分析ツール等に使われます。
正解データを与えて機械学習させる「教師あり学習」とは反対の発想です。(詳しくは前回の勉強会レポートをご覧ください)
中島さん:
「今回はK-meansを用いて教師なし学習を実際にやってみます」
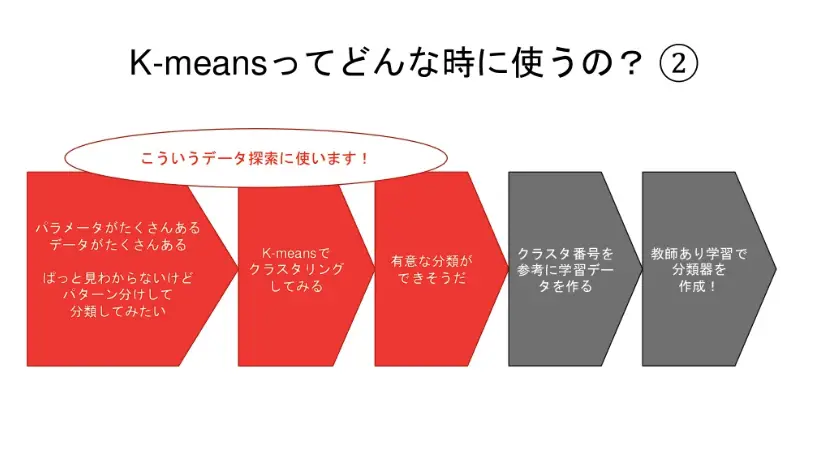
K-means(K平均法)とはクラスタ分析手法の一つです。乱雑なデータを類似のもの同士でまとめていくテクニックを指します。ぱっと見でよく分からないデータ群を「見える化」して、有益なデータとしてアウトプットできます。
1. PythonをPCに導入する

中島さんは、教師なし学習を行うため「Python」を導入することを勧めています。
中島:
「機械学習を行える言語としてJavaやScalaなどもありますが、データ分析が行いやすくライブラリも充実しているPythonがおすすめです」
中島:
「初心者はとりあえず、pyenvとanaconda2、anaconda3を入れておけばOKです。」
Pythonは現在、2008年にリリースされたPython3が最新バージョンですが、未だにPython2にしか対応していないライブラリが多くあるためPython2と3を併用するのが主流です。
そこで便利なのがpyenv。pyenvとは、複数バージョンのPythonを簡単に切り替えられる環境管理ツールです。
またanacondaは、Pythonでよく利用されるライブラリをセットにしたPythonパッケージです。
2. jupyter-notebookで新規ファイルを作成&データを読み込んでみる
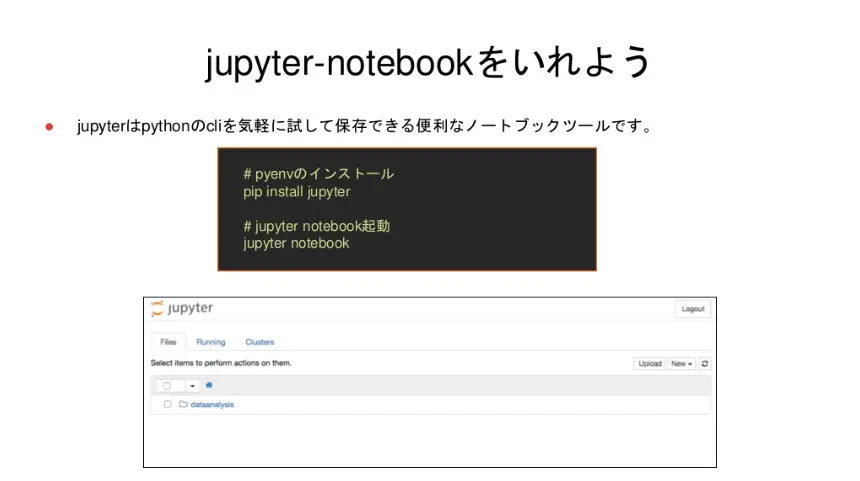
中島さん:
「次に、jupyter-notebookを入れておくと便利でしょう」
jupyter-notebookはPythonのcilを気軽に実行・保存できる便利なノートブックツールです。自分の作業の過去ログや、開発メンバーへ作業結果をシェアする際に活用します。
開発環境を整えたところで、さっそく開発開始です。
中島さん:
「今回はエンジニアのスキルレベルのクラスタ分析をやってみます」
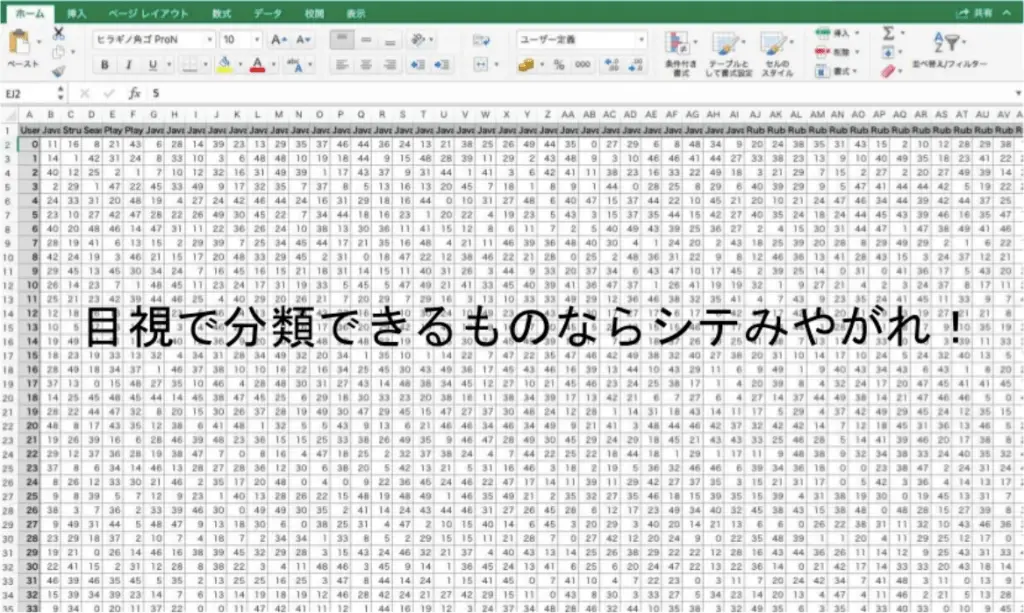
中島さんは、クラウドソーシングサービスに登録されているハイスキルなエンジニアたちがこなしてきた案件を関連スキルごとにまとめた(架空の)Excelデータを用意してくれました。
対象のハイスキルエンジニアは3,000人、スキルの種類は150種類。とても目視で分類できる数ではありません!
3. 新しいnotebookを作る
 jupyter-notebookのNewタブから、Python3をクリックして新しいノートブックを作成します。
jupyter-notebookのNewタブから、Python3をクリックして新しいノートブックを作成します。

最初にPandas、numpy、scikit-learn、matplotlibというライブラリを読み込んでおきます。
Pandasは、Excelファイルをそのまま読み込んでデータフレームを作成できる非常に強力なツールです。
中島さん:
「機械学習のライブラリであるPandas、numpyを使いこなすことが一番の近道です」
中島さん:
「このデータベースを使うためにPythoneを使うといっても過言ではない」
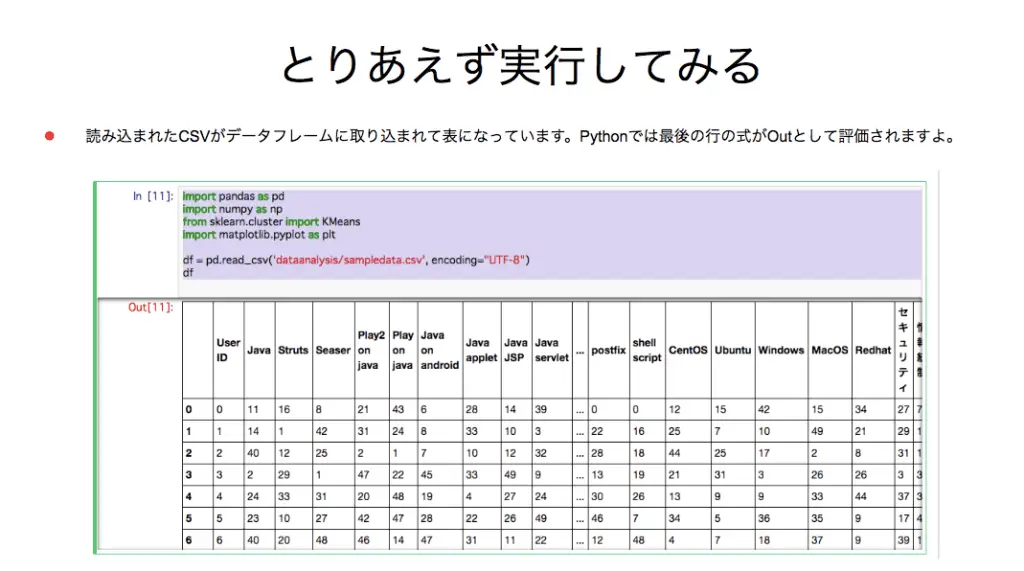
Pandasのread_csvという関数でcsv(表形式ファイル)を読み込みます。
プログラムを実行してみると、上記のようにデータフレームに取り込まれ、表として表示されます。
4. クラスタリングのためデータを整備する

読み込んだデータをクラスタリング(複数のデータをまとめてひとかたまりにすること)をするために、numpyを使用します。
中島さん:
「Numpyは数学計算ライブラリであり、行列操作から高度な演算までやってくれる非常に優秀なツールです」

実行してみると、各項目が行列になっている多次元行列が出力されました。
5. Kmeansクラスでクラスタリングする
続いて出力されたデータをK-meansでクラスタリングします。

中島さん:
「難しいことは考えず、クラスタ数を4に指定してクラスタ番号を予測してみましょう。」
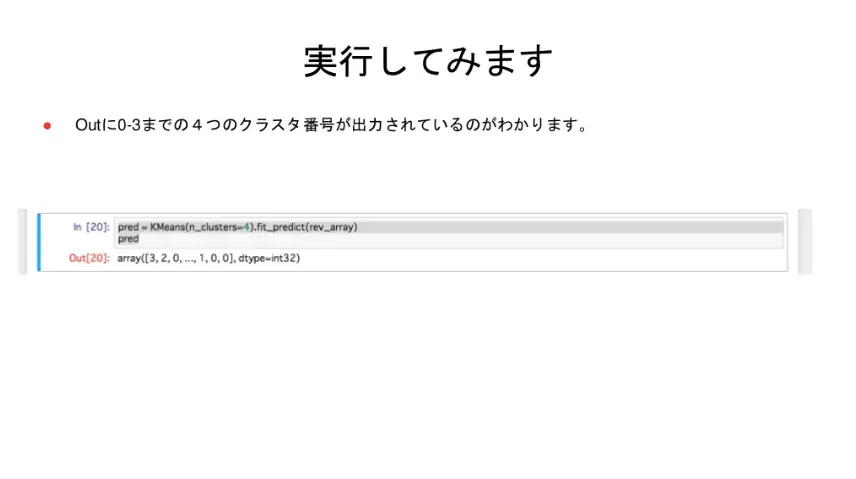
実行すると、4つのクラスタ番号が出力されます。
6. データフレームにくっつける
最後に出力されたデータを、データフレームにくっつける作業を行います。
中島さん:
「入力するコードは、たったこれだけ。めちゃめちゃ楽。Pandasのデータフレームは本当に優秀です」
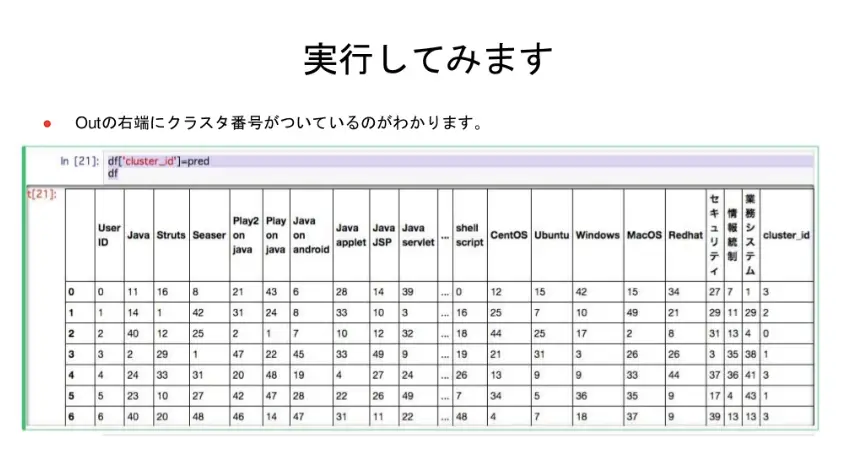
dfデータセットのフィールドcluster_idとして先ほど取得したクラスタ番号の配列を代入すると、ループ処理なしで右端にクラスタ番号をくっつけることができます。
最初のExcelデータと比べると、整理されたデータが得られましたね。
中島さん:
「このデータフレームを使って、様々な”使える”データを抽出しましょう」
中島さん:
「クラスタごとのデータ数の表示や、平均値の算出、基本統計量をクラスタごとに表示するなども可能。グラフも出力できます」
教師なし学習 Q&A
最後に会場からの質問タイムを設けました。
Q:
競馬の予測システム等も、過去のデータを参照して教師なし学習をしている?
A:
何が勝因に影響しているかデータ選定をする必要はあるが、普通に行われていると思う。
中島さん:
「ちなみに教師なし学習は、データが多ければ精度が高くなるとは限りません。余計なデータが増えることで、精度がブレることも多々あります」
中島さん:
「データの種類を増やすより、キラーファクターを正しく選定することが大事です。例えばAmazonのレコメンド機能は、わずかな種類のデータだけでおすすめ商品を表示しているとの噂です」
まとめ

勉強会のあとは懇談会のお時間です! 参加者の皆さまは各々お好きなお酒・ソフトドリンクを手に取り、乾杯致しました!

某有名中華料理店のオードブルを囲み、自由に和気あいあいと団らんしました。社内外関係なく交流できる場はとても貴重です。
(なお、余ったご飯のオードブル2つ分は全て僕が持ち帰りました。ありがてぇ)

GIGでは月1回のペースで社外向けの勉強会を開催しています。エンジニアに限らず、デザイナーやディレクターなども勉強会に参加しており、全社的なスキル向上の良い機会となりました。
僕はバックエンドのプログラミングに関しては疎かったのですが、「この機会にPythonをイジってみようかな……?」なんて思いました。中島さんがおっしゃっていた通り、とりあえずpyenvとanacondaを入れてみようと思います。
GIGでは機械学習、IoT、ブロックチェーンなどの最新トレンドに関する勉強会を今後も定期的に開催していきます。イベントの詳しい情報は、connpassのGIGページをチェックしてください!
WebやDXの課題、無料コンサル受付中!

じきるう
早稲田大学および同大学院卒。2018年に株式会社GIGに入社後、メディア事業部長、マーケティング事業部長を経て現在はCMO。日本最大級のHR・フリーランスメディア『Workship MAGAZINE』ほか、数々のメディアのプロデュースを担当。書籍『デザインの言語化』『フリーランスの進路相談室』『ADHD会社員、フリーランスになる。』『マンガでわかる!フリーランスの生き残り戦略』など監修・編集。ウイスキーが好き。
SHARE